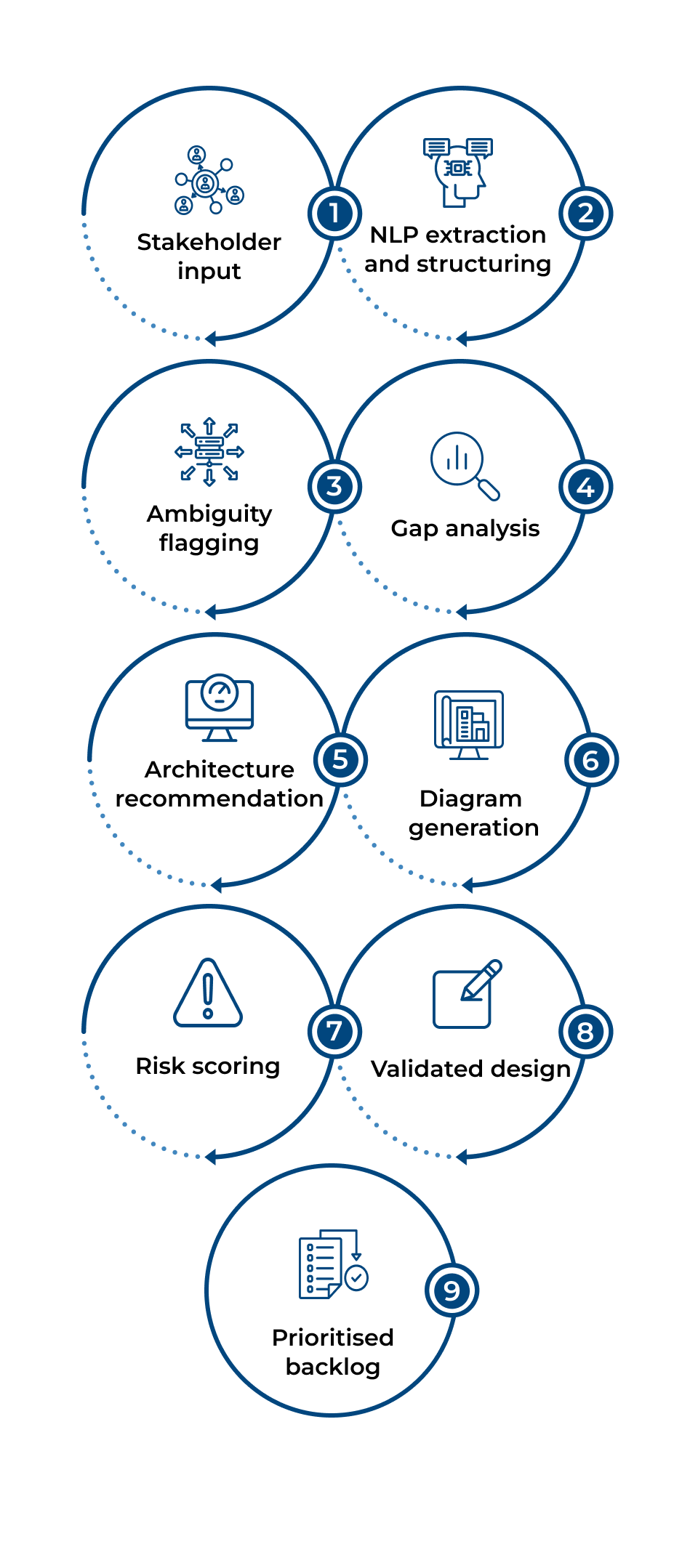
NLP-based requirement extraction from documents, meetings, and tickets that are structured and de-duplicated

Ambiguity detection and gap analysis before backlog sign-off

Acceptance criteria and edge case generation directly from user stories

AI-suggested architecture patterns with explicit anti-pattern identification

ERD, sequence diagram, and flow generation from plain-English descriptions

Tools: Claude, ChatGPT, Eraser.io, Mermaid AI, Notion AI





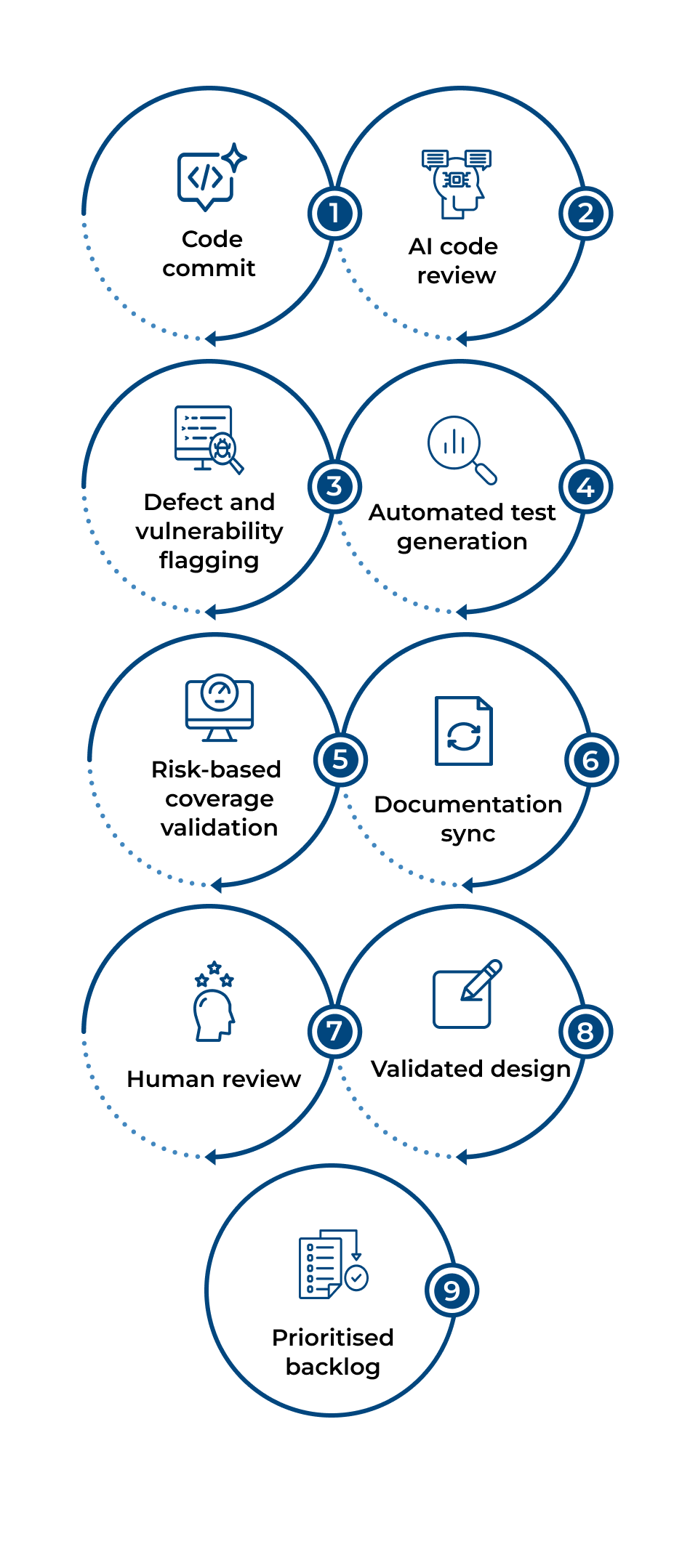
AI pair programming embedded in the IDE across all active development

Automated code review on every pull request: logic errors, security issues, style violations

Automated unit, integration, and edge-case test suite generation from code and requirements

Risk-based test prioritisation: coverage focused on highest-defect-probability areas first

Auto-generated living documentation: API references, architecture decision records, runbooks

Tools: Cursor, GitHub Copilot, CodiumAI, Diffblue, Mintlify, Swimm





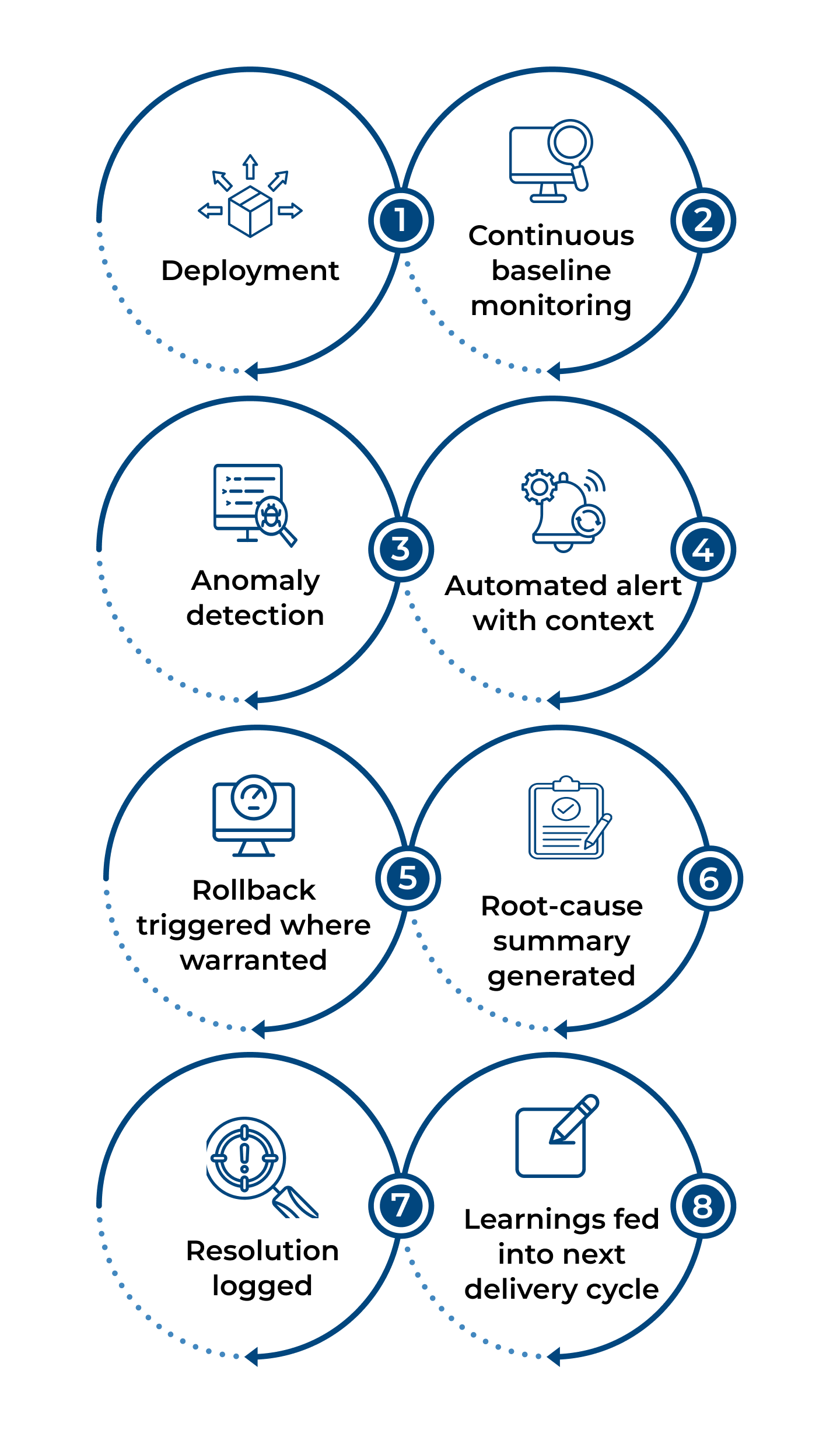
AI anomaly detection trained on service baselines catches deviations before users are affected

Predictive alerting with noise filtering: fewer false positives, faster response to real events

Incident summarisation with AI-generated root-cause analysis on failure events

Automated rollback triggers based on live performance signals, not manual thresholds

Integrated into existing monitoring stacks with no rip-and-replace

Tools: Datadog AI, Grafana, PagerDuty AI